Abstract
The repository is responsible for providing persistent storage of RDF graphs along with the other aspects included in the ACID(++) concept:
Transactional properties - atomicity, concurrency
Security - user authentication, access control
Maintainability - backup/restore, statistics, logging
Scalability
The primary repository implementation by SCAM utilizes the Enterprise JavaBean 2.0 (EJB) concept together with a relational database to provide a persistent and scalable storage facility. The database can be just about any SQL-enabled relational database (RDB). The business logic has been divided into several EJBs each responsible for a specific set of operations. The EJBs are Stateless Session Beans using Bean Managed Persistance (BMP). A package developed by HP Labs called Jena is used to assist in the RDF-RDB layer. Jena is also used throughout the entire SCAM architecture providing an API against RDF. Future refactoring of the repository may include replacing Jena with an Entity Bean solution.
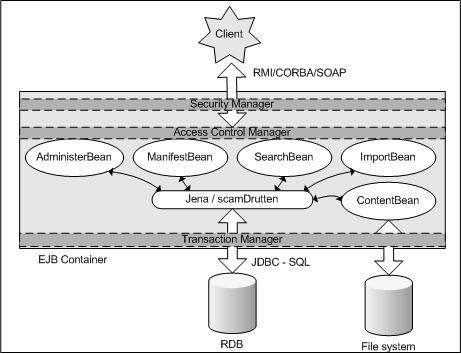
The current version of the repository uses JBoss v3.2.x, but should be easily ported to other EJB containers. Some problems are involved in this concerning deployment descriptors etc. which are not included in the EJB standard.
Table of Contents
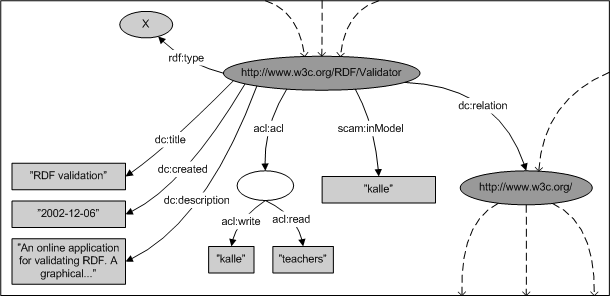
One of the main advantages of using RDF as your backend storage format is that you do not have to modify it when the data structure changes. This derives from the fact that all metadata schemas can be described using RDF. The Repository uses a Component-centric approach in its API, enabling a more intuitive way of interacting with RDF. A Component X in SCAM-sence is a subgraph defined as having an URI X as root-node ending with either a literal or another URI. This graph can consist of several blank nodes (bNodes) in between which are RDFs definition of nodes having no URI. Outspoken, this graph is the metadata about X.
SCAM natively incorporates an RDF-binding of IMS Content Packaging (IMSCP) as the organizational schema. Roughly an IMS Manifest consists of two different types of Components: Resources and Items. An Item is simply a Component being typed as an IMS Item. This little differance significantly changes the way the repository treats the Component. For instance if you remove an Item, all its sub-items will also be removed. It is analogous to when you remove a folder in a filesystem, all its sub-folders and files will be removed. In other words, you can compare how a filesystem treats files, softlinks and folders to how the repository treats Items and Resources. An Item corresponds to a softlink or a folder depending on its structure, and a Resource corresponds to a file. Having stated that, we can deduce that an Item is a collection of Components or a reference to a Resource. A Manifest is a collection of Components assigned in a certain context and can therefore be compared to a filesystem account.
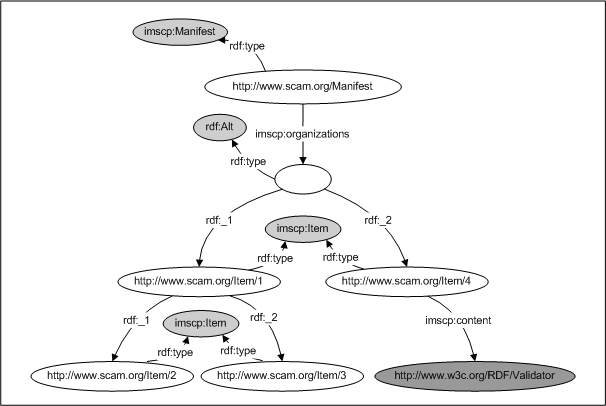
You can think of the repository data as a huge graph consisting of arcs and nodes. A Manifest is a subset of this data which in turn is divided into smaller subgraphs called Components. Note that there is a big difference between the term Manifest as opposed to the term manifest-component. A Manifest is the collection of all triples assigned in a certain context, a manifest-component is the "root" of an IMSCP hierarchy assigned to contain information about the Manifest it resides in. Also note that the term URI (Uniform Resource Locator) or URN (Uniform Resource Name) is not enough to identify a Component in SCAM. Additionally you have to specify in which context (Manifest) you are refering to it.
Items provide the means to hierarcically organize Resources, but they also allow attaching context-dependant information to its referenced Resource. You can think of an Item as a specialized view of a Resource, extending and/or overriding the original metadata.
The IMS Content Packaging structure is preserved and validated by the repository which also defines methods to change it. There are however no limitation or validation of the actual metadata which constitutes a Component. This is the case because SCAM has been designed to handle all kinds of metadata-schemas. It is hard to define a general validation service because of a graph's inherant dynamic characteristics. This has not been considered to be a prioritized service, but may very well be included at a later stage.
SCAM utilizes a strict type convention, i.e. a single RDF.type-property is required for all Components.